▶ 그룹(GROUP) 함수
- 그룹 함수 : N개의 값을 읽어서 1개의 결과 반환
하나 이상의 행을 그룹으로 묶어서 연산하여 총합, 평균 등 하나의 결과 행으로 반환하는 함수
1) SUM(숫자가 기록된 컬럼명) : 합계
-- EX) EMP 테이블에서 모든 직원의 급여 합 조회
SELECT SUM(SALARY) "전 직원 급여 합" FROM EMPLOYEE;
2) AVG(숫자가 기록된 컬럼명) : 평균
-- EX) EMP 테이블에서 모든 직원의 급여 평균 조회
SELECT AVT(SALARY) FROM EMPLOYEE;
3) MIN (컬럼명) : 최소값
MAX (컬럼명) : 최대값
→ 타입 제한 없음 (숫자: 대/소, 날짜: 과거/미래, 문자열: 문자 순서)
-- EX) EMP 테이블에서 가장 낮은 급여, 가장 빠른 입사일, 알파벳 순서가 가장 빠른 이메일 조회
SELECT MIN(SALARY), MIN(HIRE_DATE), MIN(EMAIL) FROM EMPLOYEE;
-- EX) EMP 테이블에서 가장 높은 급여, 가장 늦은 입사일, 알파벳 순서가 가장 늦은 이메일 조회
SELECT MAX(SALARY), MAX(HIRE_DATE), MAX(EMAIL) FROM EMPLOYEE;
4) ★★★ COUNT( * | 컬럼명) : 행 개수를 헤아려서 리턴
- COUNT( [DISTICT] 컬럼명) : 중복을 제거한 행 개수를 헤아려서 리턴
- COUNT( * ) : NULL을 포함한 전체 행 개수를 리턴
- COUNT(컬럼명) : NULL을 제외한 실제 값이 기록된 행 개수를 리턴
-- EX) EMP 테이블에서 전체 행의 개수(== 전체 직원 수) 구하기
SELECT COUNT(*) FROM EMPLOYEE;
-- EX) EMP 테이블에서 DEPT_CODE가 NULL이 아닌 행의 개수
SELECT COUNT(DEPT_CODE) FROM EMPLOYEE;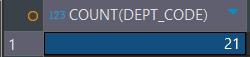
※ COUNT(컬럼명) : NULL을 제외한 실제 값이 기록된 행 개수를 리턴
-- EX) EMP 테이블에서 남자 직원 수 조회
SELECT COUNT(*) FROM EMPLOYEE WHERE SUBSTR(EMP_ID,8,1)=1;SELECT COUNT(
CASE
WHEN SUBSTRE(EMP_ID,8,1) =1 THEN '남자'
END) 남자
FROM EMPLOYEE;SELECT SUM(DECODE(SUBSTR(EMP_ID,8,1),1,1)) FROM EMPLOYEE;


-- EX) EMP 테이블에 있는 부서의 개수
SELECT COUNT(DISTINCT DEPT_CODE) FROM EMPLOYEE;※ 부서 코드의 개수를 파악하면 부서의 개수를 알 수 있음. DISTINCT로 중복값 제거
※ 7행의 결과가 있지만 1행이 NULL이기 때문에, COUNT 시 제외되어 6행 조회됨

'SQL > 기본 개념' 카테고리의 다른 글
| JOIN (0) | 2024.12.16 |
|---|---|
| GROUP BY / HAVING (0) | 2024.12.16 |
| 함수 (0) | 2024.12.16 |
| SELECT (DML / DQL) (2) | 2024.12.16 |
| Database 개요 (0) | 2024.12.16 |